How Does Redis Streams Work and When Should We Use it?
What is Redis Streams?
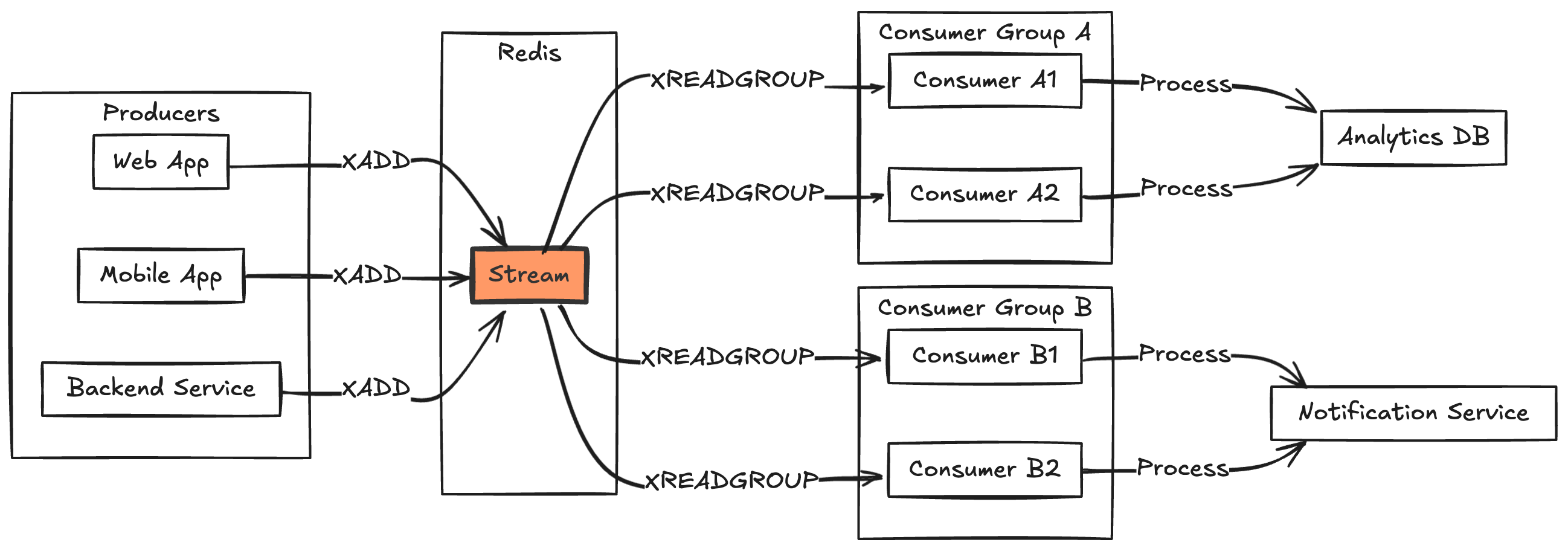
Redis Streams is a data structure introduced in Redis 5.0 that acts as a log-like append-only data structure, perfectly designed for handling ordered message flows. Think of it as a specialized message broker built directly into Redis, combining the simplicity of a Redis List with the durability and consumer group features of traditional message queues like Kafka.
Core Concepts and Architecture
1. Stream Entry Structure
Each entry in a Redis Stream has three components:
- ID: A unique identifier in the format
timestamp-sequence(e.g.,1678452553123-0) - Field-Value Pairs: Collection of named fields and their corresponding values
- Metadata: Information about when the message was added and its position
ID: 1678452553123-0
{
"user_id": "u1001",
"action": "purchase",
"product_id": "p5432",
"amount": "129.99"
}
This structure allows for both ordered access by ID and content-based filtering.
2. Consumer Groups Mechanism
Similar to Kafka consumer groups, Redis Streams supports consumer group semantics:
Consumer Group: "payment-processors"
├── Consumer-1: Processing entries 0-999
├── Consumer-2: Processing entries 1000-1999
└── Consumer-3: Processing entries 2000-2999
Each consumer group maintains:
- Last-Delivered-ID: Highest ID delivered to the group
- Consumer Ownership: Mapping of entries to specific consumers
- Pending Entries List (PEL): Entries delivered but not acknowledged
3. Working Principles
Message Publishing Process
- Producer calls
XADDto append new entry to stream - Redis assigns a unique ID (or uses provided ID)
- Entry is persisted to stream with O(1) complexity
Message Consumption Process
- Independent Consumers: Use
XREADto pull messages from specific position - Consumer Groups: Use
XREADGROUPfor coordinated consumption:- Automatic consumer balancing
- Message acknowledgment tracking
- Failure recovery through pending entries
Key Commands and Usage Patterns
1. Basic Stream Operations
# Add entry to stream
XADD mystream * user_id u1001 action login
# Read entries from beginning
XREAD COUNT 2 STREAMS mystream 0-0
# Read entries from specific ID
XREAD STREAMS mystream 1678452553123-0
2. Consumer Group Management
# Create consumer group
XGROUP CREATE mystream payments-group $
# Read as consumer within group
XREADGROUP GROUP payments-group consumer-1 COUNT 10 STREAMS mystream >
# Acknowledge processed messages
XACK mystream payments-group 1678452553123-0
# View pending messages
XPENDING mystream payments-group
3. Stream Information and Management
# Get stream information
XINFO STREAM mystream
# Trim stream to a maximum length
XTRIM mystream MAXLEN 10000
# Delete a range of messages
XRANGE mystream 1678452553123-0 1678452553999-0
Practical Use Cases
1. Activity Event Streams
Perfect for tracking user activities in real-time applications:
- User actions (clicks, logins, purchases)
- Audit trails with chronological ordering
- Social media feeds and notifications
Example implementation:
XADD user_activities * user_id u1001 action "product_view" product_id p5432 timestamp 1678452553123
2. Real-time Analytics Pipeline
Enable continuous processing of analytics events:
- Click-stream analysis
- Real-time metrics calculation
- Funnel analysis and conversion tracking
Architecture example:
Web Analytics Flow:
User Action → Redis Stream → Consumer Group → Time-Series DB → Dashboard
3. Distributed System Coordination
Facilitate event-driven microservices communication:
- Service-to-service events
- Workflow orchestration
- Command distribution with acknowledgments
Streams vs. Other Redis Data Structures
| Feature | Streams | Lists | Pub/Sub | Sorted Sets |
|---|---|---|---|---|
| Message Persistence | Yes (configurable) | Yes | No | Yes |
| Consumer Groups | Yes | No | No | No |
| Random Access | Yes (by ID) | No | No | Yes (by score) |
| Acknowledgments | Yes | No | No | No |
| Message Format | Field-Value Pairs | String | String | Score-Value |
| Memory Efficiency | High | Medium | N/A | Medium |
Redis Streams vs. Kafka: When to Choose Which?
Choose Redis Streams When:
- Data Scale: Processing < 1TB of data per day
- Infrastructure: Seeking simplicity in deployment and operations
- Retention: Message history needs are moderate (hours to days)
- Integration: Already using Redis for other components
- Latency: Sub-millisecond processing is required
Choose Kafka When:
- Data Scale: Processing > 1TB of data per day
- Retention: Long-term storage (days to years) is needed
- Ecosystem: Requiring integration with Hadoop, Spark, etc.
- Partitioning: Advanced partition management is required
- Multi-DC: Cross-datacenter replication is essential
Performance Optimization
1. Memory Management
# Limit stream length to prevent memory issues
XTRIM mystream MAXLEN ~ 100000
# Use approximate trimming for efficiency
XTRIM mystream MAXLEN ~ 100000
2. Consumer Group Optimization
- Process messages in batches (10-100 entries)
- Acknowledge messages in batches to reduce network round-trips
- Set appropriate timeouts for blocking operations
3. Monitoring and Metrics
# Important metrics to monitor
XINFO STREAM mystream # Stream length and details
XINFO GROUPS mystream # Consumer group status
XINFO CONSUMERS mystream grp # Individual consumer lag
Common Issues Troubleshooting
1. Consumer Lag
Symptoms:
- Growing number of XPENDING entries (backlog of unacknowledged messages)
- Rapid increase in stream length (production rate exceeds consumption rate)
- Decreasing real-time processing capability, affecting business response time
Solutions:
- Add more consumer instances: Scale horizontally to increase parallel processing
- Optimize processing logic: Reduce per-message processing time, consider async processing for non-critical steps
- Enable batch acknowledgment: Use
XACKwith multiple IDs to reduce network overhead
2. Memory Pressure
Symptoms:
- Rising Redis memory usage (observable via INFO memory command)
- Increasing response time (due to memory swapping or fragmentation cleanup)
- Potential triggering of maxmemory policy, affecting other key-value storage
Solutions:
# Auto-trim historical data (~ symbol indicates approximate trimming for better performance)
XTRIM mystream MAXLEN ~ 100000
# Configure maximum memory for stream nodes, controlling per-node memory usage
CONFIG SET stream-node-max-bytes 4096
3. Message Loss
Symptoms:
- Increasing processing error logs (client exceptions after message delivery)
- Non-continuous ID sequences (indicating messages not properly processed)
- Consumers unable to find in-process messages after restart
Solutions:
- Use
XCLAIMto recover unacknowledged messages: Allow other consumers to take over long-pending messages - Implement client retry mechanisms: Log and retry on failure to prevent message loss
- Enable persistence: Ensure AOF persistence is configured as 'always' to prevent data loss during server failures
Summary
Redis Streams provides a powerful and accessible way to implement message-driven architectures within Redis. Its combination of durability, consumer groups, and performance makes it ideal for real-time data processing use cases. While not a direct replacement for dedicated message brokers like Kafka for very large-scale applications, Streams offers an excellent solution for many real-time data pipeline needs.
Related Topics: