Redis Streams 是如何工作的?适用于什么样的场景?
Redis
流式处理
消息队列
实时处理
数据管道
什么是 Redis Streams?
Redis Streams 是 Redis 5.0 引入的日志式数据结构,专为处理有序消息流设计。它结合了 Redis List 的简洁性和 Kafka 等消息队列的持久化特性,可以看作是 Redis 内置的轻量级消息代理。
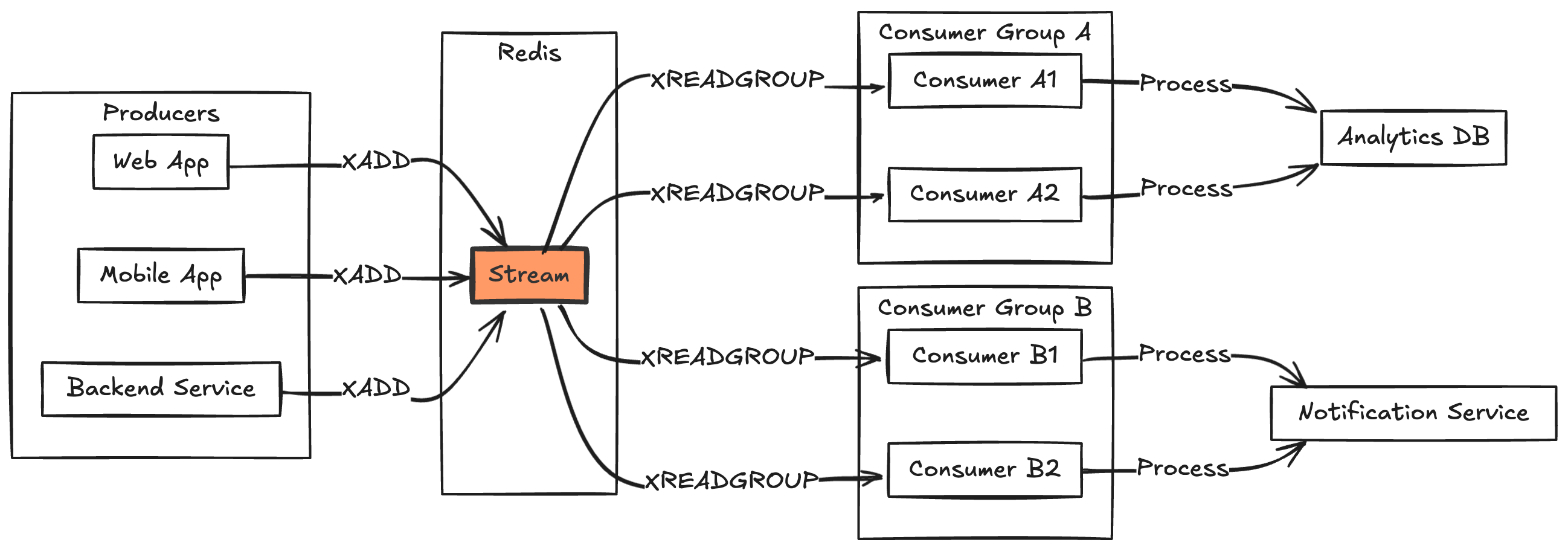
核心概念与架构
1. 消息结构
每个 Stream 条目包含三个核心组件:
- ID:唯一标识符,格式为
时间戳-序列号(如1678452553123-0) - 键值对:可自定义的字段集合
- 元数据:消息添加时间和位置信息
ID: 1678452553123-0
{
"user_id": "u1001",
"action": "purchase",
"product_id": "p5432",
"amount": "129.99"
}
这种结构支持按 ID 顺序访问和基于内容的过滤。
2. 消费者组机制
类似 Kafka 的消费者组,Redis Streams 提供协同消费能力:
消费者组: "payment_group"
├── consumer1: 处理 0-999 号消息
├── consumer2: 处理 1000-1999 号消息
└── consumer3: 处理 2000-2999 号消息
每个消费者组维护:
- 最后投递ID:记录已投递的最大ID
- 消费关系映射:消息条目与消费者的对应关系
- 待确认列表(PEL):已投递但未确认的消息
3. 工作原理
消息发布流程
- 生产者通过
XADD追加新消息 - Redis 分配唯一ID(或使用指定ID)
- 消息以 O(1) 复杂度持久化到流
消息消费流程
- 独立消费者:使用
XREAD从指定位置拉取 - 消费者组:通过
XREADGROUP实现:- 自动负载均衡
- 消息确认跟踪
- 故障恢复机制
关键命令与使用模式
1. 基础操作
# 添加消息到 Streams
XADD mystream * user_id u1001 action create amount 299.00 currency CNY
# 从起始位置读取2条消息
XREAD COUNT 2 STREAMS mystream 0-0
# 从指定ID读取
XREAD STREAMS mystream 1678452553123-0
2. 消费者组管理
# 创建消费者组
XGROUP CREATE mystream payment_group $ MKSTREAM
# 消费者读取消息
XREADGROUP GROUP payment_group consumer1 COUNT 10 STREAMS mystream >
# 确认已处理消息
XACK mystream payment_group 1678452553123-0
# 查看待处理消息
XPENDING mystream payment_group
3. 流管理
# 获取流信息
XINFO STREAM mystream
# 裁剪流至10000条
XTRIM mystream MAXLEN 10000
# 删除指定范围消息
XRANGE mystream 1678452553123-0 1678452553999-0
典型应用场景
1. 用户行为事件流
适用于实时记录用户操作:
- 点击/登录/购买等事件
- 审计追踪
- 社交动态推送
实现示例:
XADD user_events * user_id u1001 action "view_product" product_id p5432 timestamp 1678452553123
2. 实时分析管道
构建持续处理的数据分析流:
- 点击流分析
- 实时指标计算
- 转化漏斗分析
架构示例:
用户行为 → Redis Stream → 消费者组 → 时序数据库 → 数据看板
3. 微服务协同
实现事件驱动的服务通信:
- 服务间事件通知
- 工作流编排
- 带确认的命令分发
Streams vs 其他数据结构
| 特性 | Streams | List | Pub/Sub | Sorted Set |
|---|---|---|---|---|
| 消息持久化 | 是(可配置) | 是 | 否 | 是 |
| 消费者组 | 支持 | 不支持 | 不支持 | 不支持 |
| 随机访问 | 按ID | 否 | 否 | 按分值 |
| 消息确认 | 支持 | 否 | 否 | 否 |
| 内存效率 | 高 | 中 | N/A | 中 |
Redis Streams vs Kafka:如何选择?
选择 Redis Streams 的场景:
- 数据规模:日处理量 < 1TB
- 基础设施:追求部署运维简单
- 保留策略:只需保留数小时到数天的历史
- 集成需求:已使用 Redis 其他功能
- 延迟要求:需要亚毫秒级处理
选择 Kafka 的场景:
- 数据规模:日处理量 > 1TB
- 保留需求:需要长期存储(数天到数年)
- 生态整合:需对接 Hadoop/Spark 等系统
- 分区管理:需要高级分区策略
- 多数据中心:需要跨机房复制
性能优化指南
1. 内存管理
# 限制流长度防止内存溢出
XTRIM mystream MAXLEN ~ 100000
# 使用近似裁剪提升效率
XTRIM mystream MAXLEN ~ 100000
2. 消费者组优化
- 批量处理消息(建议 10-100 条/批)
- 批量确认减少网络开销
- 设置合理的阻塞超时
3. 监控指标
# 关键监控项
XINFO STREAM mystream # 流长度
XINFO GROUPS mystream # 消费者组状态
XINFO CONSUMERS mystream payment_group # 消费者延迟
常见问题排查
1. 消费延迟
症状:
- XPENDING 数量持续增长(未确认消息积压)
- 流长度快速增加(生产速度超过消费速度)
- 消息处理实时性下降,影响业务响应时间
解决方案:
- 增加消费者实例:通过水平扩展提高并行处理能力
- 优化处理逻辑:减少单条消息处理时间,可考虑异步处理非关键步骤
- 启用批量确认:使用
XACK批量确认减少网络交互次数
2. 内存压力
症状:
- Redis 内存使用率攀升(可通过 INFO memory 命令观察)
- 响应时间变长(因内存交换或碎片整理导致)
- 可能触发 maxmemory 策略,影响其他键值存储
解决方案:
# 自动裁剪历史数据(~ 符号表示近似裁剪,性能更优)
XTRIM mystream MAXLEN ~ 100000
# 配置流节点最大内存,控制单个节点内存使用
CONFIG SET stream-node-max-bytes 4096
3. 消息丢失
症状:
- 处理错误日志增多(客户端异常但消息已投递)
- ID 序列不连续(表明某些消息未被正确处理)
- 消费者重启后无法找到之前处理中的消息
解决方案:
- 使用
XCLAIM回收未确认消息:让其他消费者接管长时间未处理的消息 - 实现客户端重试机制:处理失败时记录并重试,避免消息丢失
- 启用持久化:确保 AOF 持久化配置为 always,防止服务器故障导致数据丢失
总结
Redis Streams 为实时数据管道提供了高性能的轻量级解决方案。虽然不适合替代 Kafka 处理超大规模数据,但在多数实时场景中表现出色,是 Redis 生态中不可或缺的组件。
相关推荐: